コンテナイメージ脆弱性管理ツールのKubeClarityを試してみる
KubeClarity とは

KubeClarityとはKubernetes環境におけるセキュリティ管理を支援するオープンソースツールです。 具体的にはKubernetes上に存在するコンテナイメージのSBOMを生成し、SBOMを元に脆弱性スキャンを行います。 そしてスキャン結果をWeb UI上で見ることができます。
SBOMの生成にはデフォルトではSyftが使用され、SBOMに対しての脆弱性スキャンにはGrypeがデフォルトで使用されます。
SBOMの生成には他にもCyclonedx-gomod、Trivyが選択可能で、SBOMに対しての脆弱性スキャンは他にもDependency-Track、Trivyが選択可能です。
Trivy Operatorとの違い
似たようなツールとしてTrivy Operatorがあります。 Trivy OperatorもKubernetes上のコンテナイメージの脆弱性スキャンを自動で行ってくれるツールですが、Web UIがないという問題があります。 またTrivy Operatorは脆弱性スキャン結果をKubernetesのカスタムリソースとして保存しますが、KubeClarityはDB内に保存します。
Web UIがあるというのは非常に魅力的なので今回KubeClarityを試してみました。
方法インストール
今回はEKS上にインストールしてみました。
まずはeksctlを使ってEKSクラスタを作成します。
eksctl create cluster --name my-k8s --version 1.29 --nodegroup-name my-standard-workers --node-type t3.medium --nodes 2 --nodes-min 2 --nodes-max 2
次にOICDプロバイダーを作成します。
eksctl utils associate-iam-oidc-provider --cluster my-k8s --approve
KubeClarityは脆弱性情報の保存にDBを使います。KubeClarityがPostgreSQL Podを立ててくれますが、PersistentVolumeリソースが必要となります。 今回はPersistentVolumeリソースのストレージとしてEBSを使います。 もしEKS on Fargateをお使いの場合はEBSを選ぶことができずEFSを使うことになります。 (もしとりあえず動かしたいというだけならkubeclarity-kubeclarity-postgresql StatefuleSetのvolumeClaimTemplatesを消してemptyDirを使うようにすればEBS/EFSなしで動きます)
EKSからEBSを簡単に作成するために、Amazon EBS CSI ドライバーアドオンをEKSにインストールします。 アドオンをインストールする前に、アドオンが使うIAM RoleとServiceAccountを作成します。
eksctl create iamserviceaccount --name ebs-csi-controller-sa --namespace kube-system --cluster my-k8s --role-name "AmazonEKS_EBS_CSI_DriverRole" --role-only --attach-policy-arn arn:aws:iam::aws:policy/service-role/AmazonEBSCSIDriverPolicy --approve
Amazon EBS CSI DriverアドオンをEKSにインストールします。 先ほど作成したIAM Roleを指定するのがポイントです。
eksctl create addon --name aws-ebs-csi-driver --cluster my-k8s --service-account-role-arn arn:aws:iam::アカウントID:role/AmazonEKS_EBS_CSI_DriverRole --force
アドオンがインストールされたことを確認します。
eksctl get addon --cluster my-k8s NAME VERSION STATUS ISSUES IAMROLE UPDATE AVAILABLE CONFIGURATION VALUES aws-ebs-csi-driver v1.32.0-eksbuild.1 ACTIVE 0 arn:aws:iam::アカウントID:role/AmazonEKS_EBS_CSI_DriverRole
# EBS CSI DriverのPodが作成され、Runningになっていることを確認 kubectl get pod -n kube-system | grep ebs ebs-csi-controller-76bd8c75-48zb5 6/6 Running 0 2m9s ebs-csi-controller-76bd8c75-vkwbt 6/6 Running 0 2m9s ebs-csi-node-gk27q 3/3 Running 0 2m9s ebs-csi-node-qptkt 3/3 Running 0 2m9s
そしてhelmを使ってKubeClarityをインストールします。
helm repo add kubeclarity https://openclarity.github.io/kubeclarity helm show values kubeclarity/kubeclarity > values.yaml helm install --values values.yaml --create-namespace kubeclarity kubeclarity/kubeclarity -n kubeclarity
最後にKubeClarity関連のPodが正常に起動していることを確認します。
kubectl get pod -n kubeclarity NAME READY STATUS RESTARTS AGE kubeclarity-kubeclarity-8499c4b89-k684s 1/1 Running 0 3m13s kubeclarity-kubeclarity-grype-server-7655bb8cc4-t8bhl 1/1 Running 0 3m13s kubeclarity-kubeclarity-postgresql-0 1/1 Running 0 3m12s
kubeclarity-kubeclarity-postgresql-0 Podが上手く起動しない場合は、PersistentVolume関連が原因なので、PersistentVolumeリソースやPersistentVolumeClaimリソースを確認してください。
kubectl get pv NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS VOLUMEATTRIBUTESCLASS REASON AGE pvc-86f96475-b774-4806-98d3-cb0b68f9bd87 8Gi RWO Delete Bound kubeclarity/data-kubeclarity-kubeclarity-postgresql-0 gp2 <unset> 52m kubectl get pvc -n kubeclarity NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS VOLUMEATTRIBUTESCLASS AGE data-kubeclarity-kubeclarity-postgresql-0 Bound pvc-86f96475-b774-4806-98d3-cb0b68f9bd87 8Gi RWO gp2 <unset> 52m
機能、画面
インストールが終わったら、port forwardをして、
kubectl port-forward -n kubeclarity svc/kubeclarity-kubeclarity 9999:8080
http://localhost:9999 にアクセスすれば、KubeClarityの画面にアクセスできます。

まだコンテナイメージの脆弱性のスキャンがされていないので、No dataになっています。
コンテナイメージの脆弱性のスキャンをしてみます。左のメニューのRuntime Scanを選択します。

右上のSTART SCANをクリックすると、コンテナイメージの脆弱性のスキャンが開始されます。
開始するとscannerから始まるJobが生成されるのが分かります。
高速な脆弱性のスキャンをうたっているだけあって、スキャンはすぐに終わります。
kubectl get job -A NAMESPACE NAME COMPLETIONS DURATION AGE kube-system scanner-aws-ebs-csi-driver-cc8a87b7-0a19-4189-accd-96f2701d6967 0/1 1s 1s kube-system scanner-aws-network-policy-agent-26360aa8-8ed5-4af8-bf9a-a0a88e 0/1 3s 3s kube-system scanner-csi-attacher-45791186-ff68-4f5f-b6c0-20fcb4c6d473 0/1 2s 2s kube-system scanner-csi-node-driver-registrar-74381e91-0154-4e13-9b5a-2858c 0/1 1s 1s kube-system scanner-csi-provisioner-d4a9bb29-63b3-48f6-aacd-93083cda8394 0/1 2s 2s kube-system scanner-csi-snapshotter-775dafbc-51d9-48bf-8b1b-227a406bf907 0/1 2s 2s kube-system scanner-livenessprobe-e788ac28-c1a6-401c-9bf7-9637c3ab5a11 0/1 2s 2s kubeclarity scanner-curl-d56c1896-76e3-4458-b04a-31f5ea927cd7 0/1 3s 3s kubeclarity scanner-grype-server-af023988-edb6-48a0-b482-aa9325941dd2 0/1 1s 1s kubeclarity scanner-kubeclarity-9a7e4d21-f680-41ac-baf0-5f740ccfb97b 0/1 2s 2s kubectl get pod -A | grep scanner kube-system scanner-aws-network-policy-agent-26360aa8-8ed5-4af8-bf9a-aq5xbb 1/1 Terminating 0 14s kube-system scanner-coredns-caeeedce-278b-4361-b60b-82e00b34d087-7jc5r 1/1 Running 0 4s kube-system scanner-csi-attacher-45791186-ff68-4f5f-b6c0-20fcb4c6d473-4hd8t 1/1 Terminating 0 13s kube-system scanner-csi-node-driver-registrar-74381e91-0154-4e13-9b5a-5rm7h 1/1 Terminating 0 12s kube-system scanner-csi-provisioner-d4a9bb29-63b3-48f6-aacd-93083cda8379qf7 0/1 Terminating 0 13s kube-system scanner-csi-snapshotter-775dafbc-51d9-48bf-8b1b-227a406bf9h6v4r 0/1 Terminating 0 13s kubeclarity scanner-curl-d56c1896-76e3-4458-b04a-31f5ea927cd7-hfbmt 1/1 Terminating 0 14s kubeclarity scanner-grype-server-af023988-edb6-48a0-b482-aa9325941dd2-srszs 0/1 ContainerCreating 0 12s kubeclarity scanner-kubeclarity-sbom-db-f02478c3-9e91-45f4-b205-e61ff7w7rh5 1/1 Running 0 6s kubeclarity scanner-postgresql-aed65e35-bef9-4d98-9017-b72572583864-gmqrm 1/1 Running 0 2s
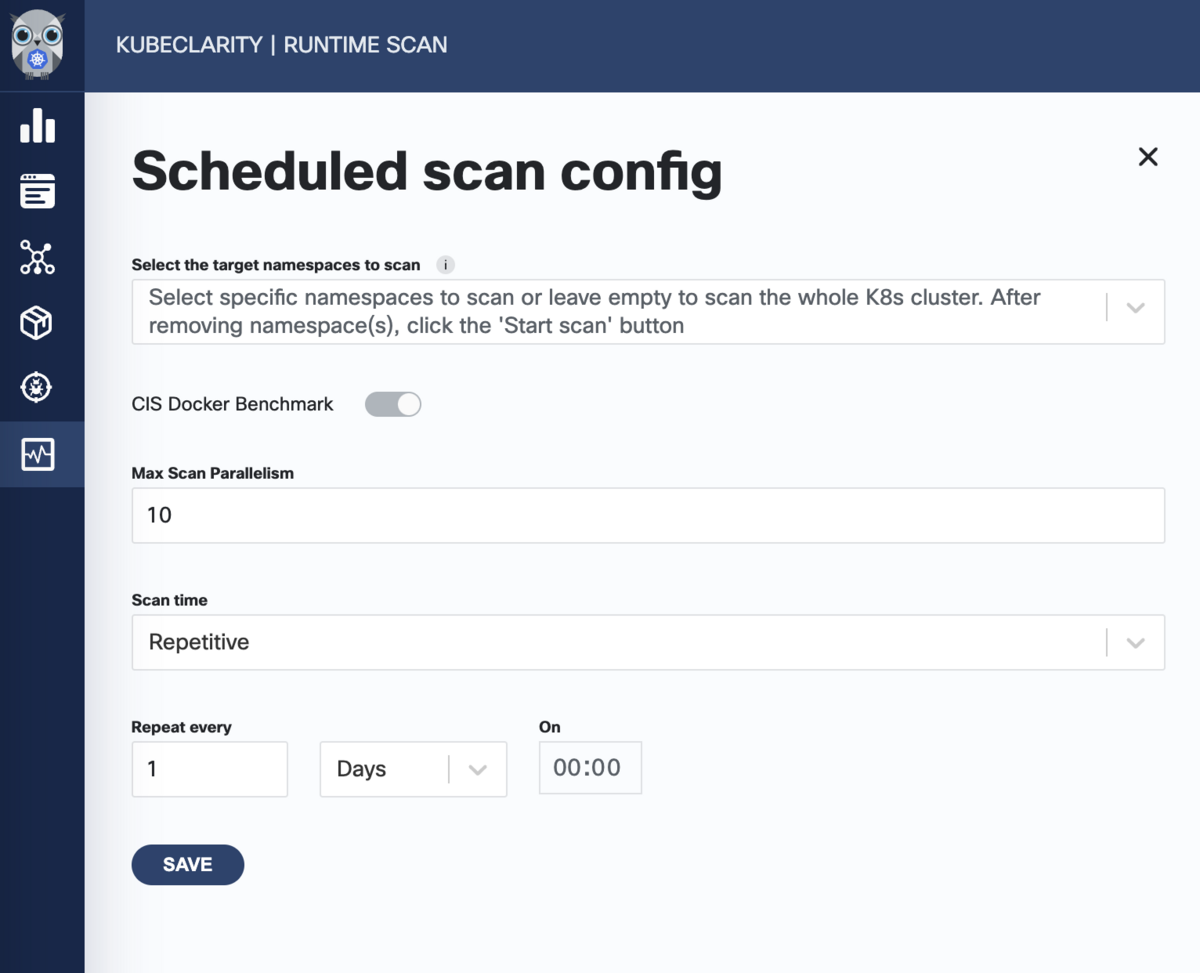
ちなみに、コンテナイメージの脆弱性のスキャンのスケジュール実行をすることもできます。
左のメニューからRuntime Scan画面に行き、右上のSchedule scanをおすと、スケジュール設定ができます。
脆弱性スキャンが終わったらこのようにProgressが100%になります。

Dashboard画面にいきますと、検知された脆弱性情報が表示されます。

こちらはApplications画面。 実行されているPodごとの脆弱性情報を見ることができます。
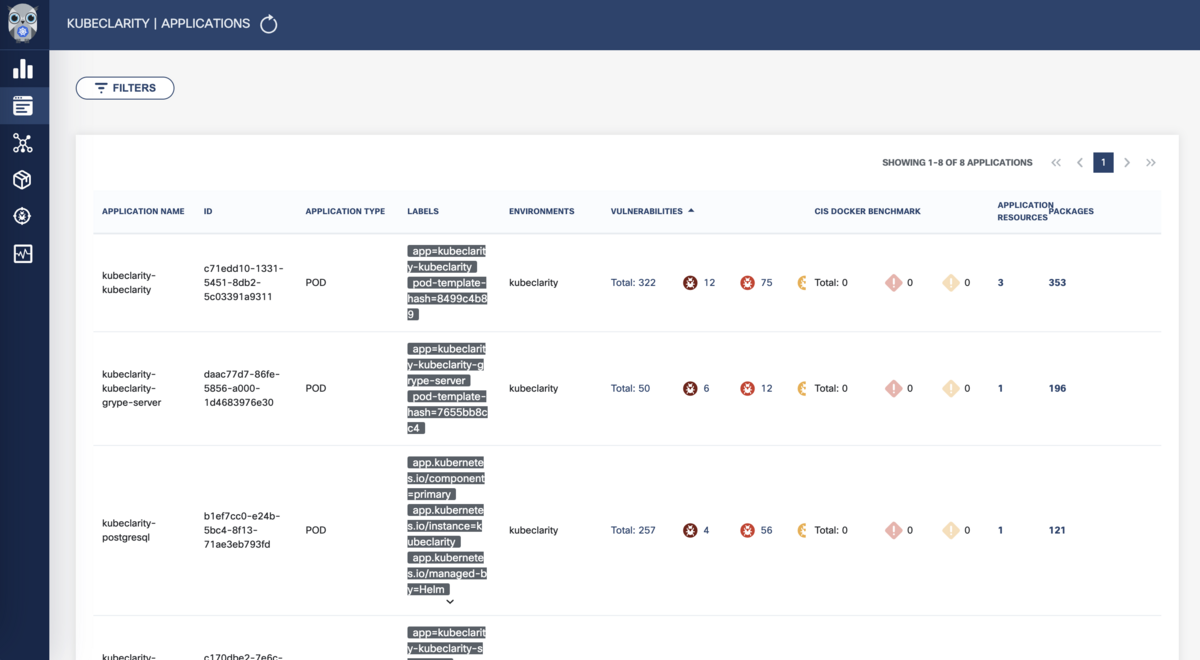
Podの脆弱性詳細画面です。

こちらはApplications Resources画面です。コンテナイメージごとの脆弱性情報を見ることができます。

こちらはPackages画面です。コンテナイメージに含まれているパッケージやライブラリごとの脆弱性情報を見ることができます。

こちらはVulnerabilities画面です。CVEごとにみることができます。 またCVEでの検索もできます。

脆弱性(CVE)詳細画面です。 脆弱性(CVE)についての説明やリンクが載っているのが嬉しいですね。

まとめ
EBSを使うのでEBSのスナップショット/リストアを考えないといけなく、その点は面倒ですが、 Web UIはとても見やすくて使いやすく出来ていました。 世の中を騒がす脆弱性が見つかった場合、うちのシステムは大丈夫なんだっけ?と調査が面倒になりますが、KubeClarityを入れていればWeb UI上から簡単にCVEを指定して脆弱性を検索できるのでとても有用そうですね。
業務ではTrivy Operatorを使っていますが、KubeClarityに乗り換えてもいいなと感じました。
ぜひみなさんもKubeClarityを使ってみてください。
Googleドキュメントのアジェンダを自動的に追加する
例えば以下のような定例用のGoogleドキュメントがあったとします。

テンプレートが下のほうにあり、上にその週のアジェンダをどんどん追加していくスタイルのドキュメントです。 ローテーションで司会が変わっていきます。
この毎週のアジェンダ作成が面倒です。テンプレートからコピってきてその週の定例の日付を入力しその週の司会の人の名前を入れる必要があります。 面倒なので自動化しました。
メニューバーの「拡張機能」から「Apps Script」を選択します。

Apps Scriptのエディタが開いたらおもむろに以下のコードを貼り付けて保存します。
var templatePhrase = 'template'; var templateDateFormat = 'YYYY/MM/DD'; var mtgIntervalDays = 7; function onOpen() { const ui = DocumentApp.getUi(); ui.createMenu('アジェンダ') .addItem('テンプレート追加', 'addTemplate') .addToUi(); } const body = DocumentApp.getActiveDocument().getBody(); var previousParagraph; var templateParagraph; const templateParagraphs = []; function setup(body) { var inTemplate = false; body.getParagraphs().forEach((paragraph) => { if (!previousParagraph && paragraph.getText().startsWith('202')) { console.log("paragraph.getText()="+ paragraph.getText()); previousParagraph = paragraph; } if (paragraph.getText().startsWith(templateDateFormat)) { templateParagraph = paragraph; } if (paragraph.getText() === templatePhrase) { inTemplate = true; return; } if (inTemplate) { templateParagraphs.push(paragraph.copy()); } }) } function getFacilitator() { var facilitatorText = templateParagraph.getText().split(" - ")[1]; // console.log(facilitatorText); facilitators = facilitatorText.match(/(.*)/g)[0].slice(1, -1).split('→'); var facilitator; if (previousParagraph == null) { facilitator = facilitators[0]; } else { var previousFacilitator = previousParagraph.getText().split(" - ")[1]; facilitators.push(facilitators[0]); facilitator = facilitators[facilitators.indexOf(previousFacilitator) + 1] } // console.log(facilitator); return facilitator; } function getMtgDate() { var previousDate; if (previousParagraph == null) { previousDate = new Date(); } else { const previousDateStr = previousParagraph.getText().split(" - ")[0]; previousDate = Utilities.parseDate(previousDateStr, "JST", "yyyy/MM/dd"); previousDate.setDate(previousDate.getDate() + mtgIntervalDays); } var mtgDate = Utilities.formatDate(previousDate, 'JST', 'yyyy/MM/dd'); // console.log(mtgDate); return mtgDate; } function addTemplate() { setup(body); // テンプレートパラグラフの挿入 var horizontalRule = body.findElement(DocumentApp.ElementType.HORIZONTAL_RULE).getElement(); var horizontalRuleIdnex = body.getChildIndex(horizontalRule.getParent()) + 1; templateParagraphs.forEach((paragraph, i) => { if (paragraph.getType() === DocumentApp.ElementType.LIST_ITEM) { body.insertListItem(i + horizontalRuleIdnex, paragraph); } else if (paragraph.getText().startsWith(templateDateFormat)) { paragraph.setText(getMtgDate() + " - " + getFacilitator()); body.insertParagraph(i + horizontalRuleIdnex, paragraph); } else { body.insertParagraph(i + horizontalRuleIdnex, paragraph); } }); }
実装の内容を簡単に説明すると、templatePhraseと一致する部分を探しそれから下をテンプレートとしてコピー、ドキュメント内の区切り線(水平線)の下にテンプレートを挿入。このときその週の日付と司会を入れる。ようにしてます。
ドキュメントに戻ると、以下のようにメニューバーに「アジェンダ」→「テンプレート追加」というメニューが追加されているのが分かると思います。

一番最初に「テンプレート追加」を押すと許可を求められますが、許可してあげてください。 そして再度「テンプレート追加」を押すと今週のアジェンダが追加されます。
さて、毎回「テンプレート追加」を手動で押すのは面倒なので、自動化します。
Apps Scriptの左のメニューから「トリガー」を選択します。

そして「トリガーを追加」を選択し、実行する関数に「addTemplate」を選択します。
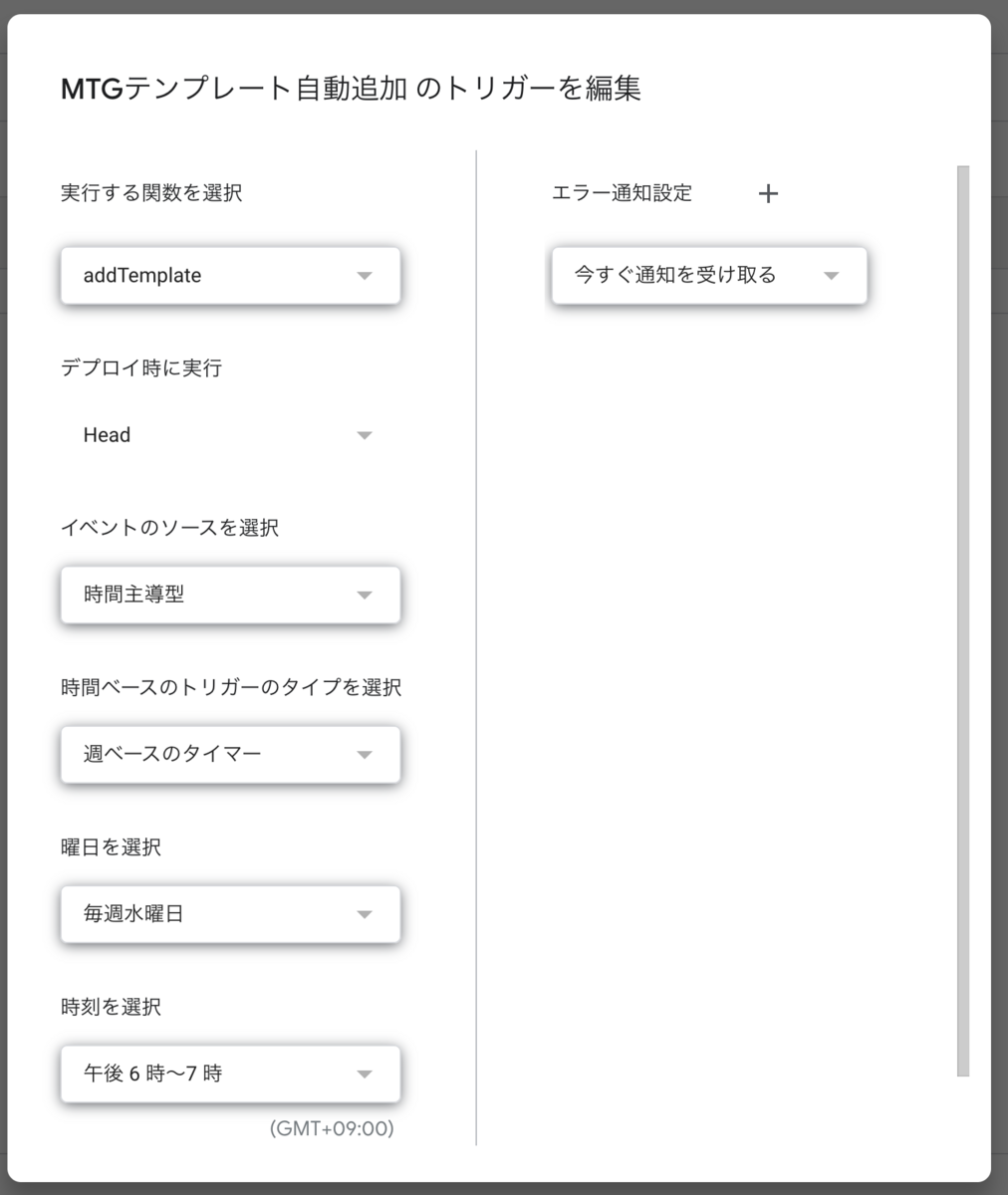
あとは実行したいスケジュール条件を入力します。定例MTGが終わった後実行するのがよいでしょう。
これで面倒な作業から解放されます。最高です。
Datadogのグラフにデプロイタイミングを表示する方法
Datadogのグラフをみていると、いつアプリケーションがデプロイされたのか気になることがあります。 「レスポンスタイムが急に悪くなってるけどデプロイ影響?」「エラーレートが跳ねるタイミングがあるけどデプロイ影響?」など。 そこでDatadogのグラフにデプロイタイミングを表示する方法を紹介します。
1, Event Overlays機能を使う
以下の画面のように、表示したいDatadog Eventのクエリを入力します。
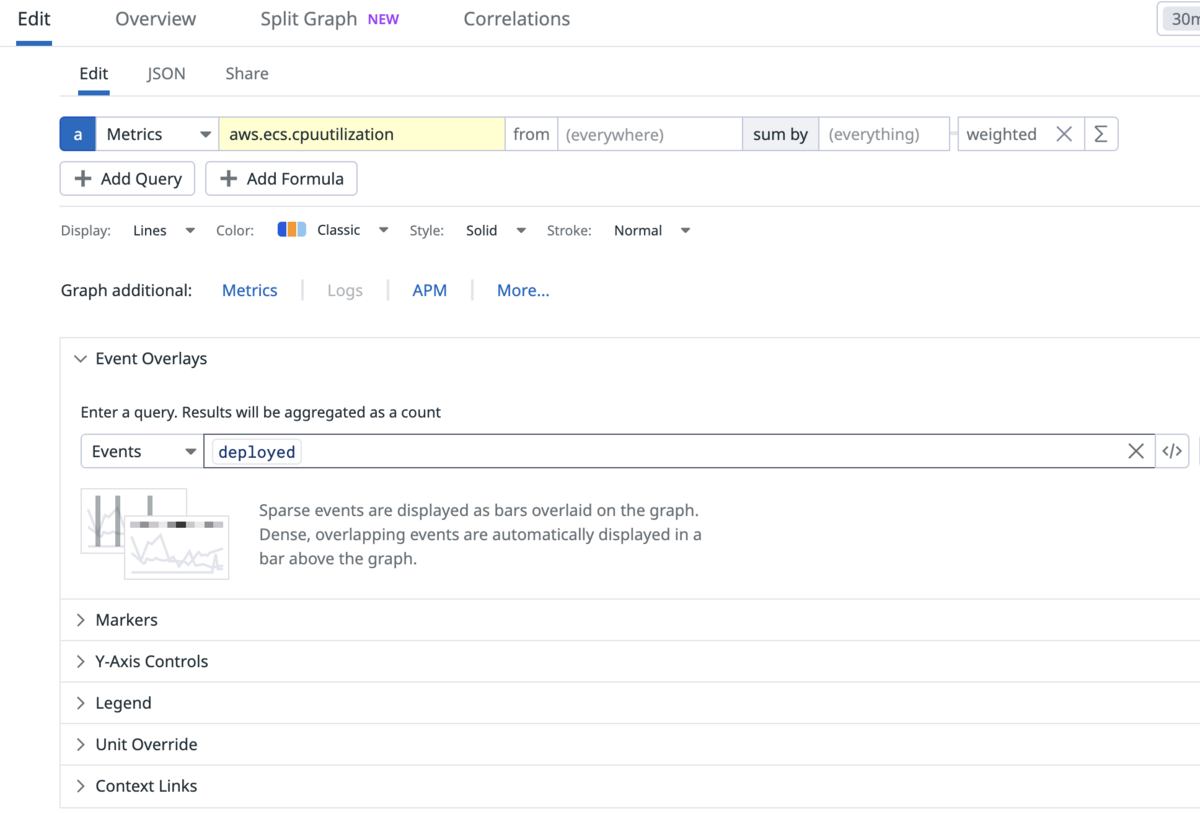
するとEvent発生日時がグラフ上に縦線で表示されます。
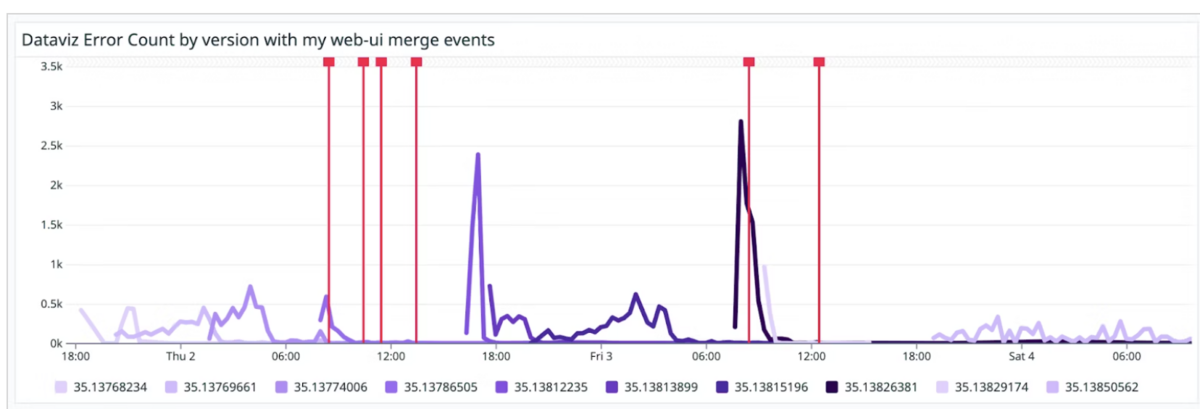
シンプルな方法ですが、デプロイするタイミングでDatadogにEventを送信する必要があります。 デプロイフローに追加が必要なのでできればDatadog内で完結したいです。
2, Show Overlays機能を使う
※これを使うにはAPMを導入し、さらにVersion情報を送る必要があります。
ダッシュボード画面の右上のShow Overlaysをクリックします。
そしてChangesを選択し、Serviceからデプロイタイミングを知りたいサービスを選択します。

すると以下のようにデプロイタイミングが表示されます。
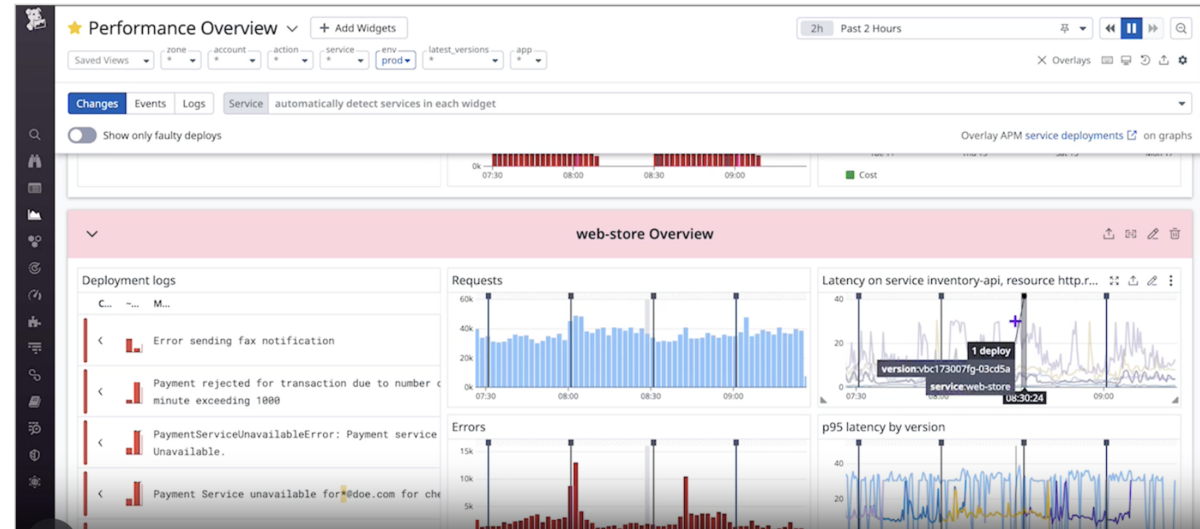
手軽でよいですが、
- ダッシュボードによっては
Show Overlaysが表示されない Show this widget in full screen( ボタン) をおしてグラフを拡大表示するとデプロイタイミングの縦棒が表示されない
ボタン) をおしてグラフを拡大表示するとデプロイタイミングの縦棒が表示されない
という課題があります。
3, Workflow Automationを使ってデプロイEventを自動で作成する
※これを使うにはAPMを導入し、さらにVersion情報を送る必要があります。
さて、本題です。
https://docs.datadoghq.com/ja/tracing/services/deployment_tracking/ docs.datadoghq.com
を読むと 「サービスの新しいデプロイが検出されるたびに、Deployment Tracking は time_between_deployments メトリクスの値を計算し、新しいデプロイとその前の最新バージョンのデプロイの間の秒数として計算されます。」とあります。そのためtime_between_deployments メトリクスを監視すればデプロイタイミングが分かります。
問題はEventをどう生成するかですが、DatadogのWorkflow Automationという機能を使います。
Workflow Automationはマイナーな機能かもしれませんが、非常に面白い機能です。 Workflow AutomationはIFTTTやZapierと似ていて、「トリガー」と「アクション」からなります。
トリガーには例えば以下が選べます
詳しくは ワークフローをトリガーする を参照ください。
アクションは、DatadogのEvent生成などDatadogへのアクションはもちろん、AWSなどのクラウドプロバイダー、SlackやGitHubなどのSaaS ツールへのアクションができます。 アクションの一覧は アクションカタログ を参照ください。
今回やりたいデプロイタイミングでDatadog Eventを生成するためには、
1, 以下の設定でworkflowを作成しておく
トリガーに「Monitor, Incident, or Security signal」を選択、アクションに「Datadog Create event」を選択
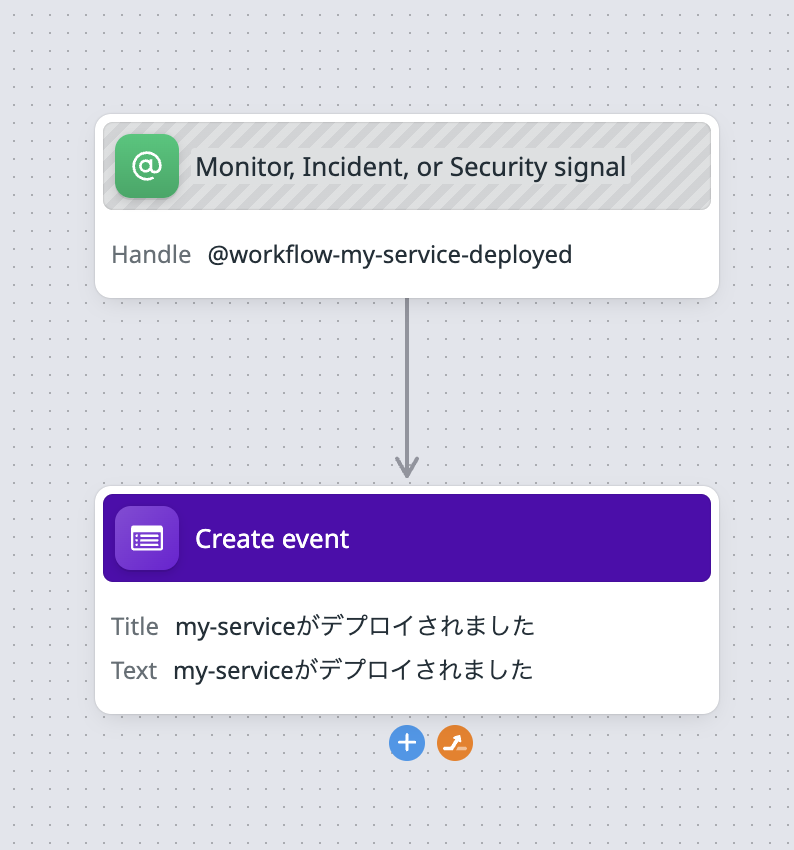
2, Monitorで time_between_deployments メトリクスを監視し0より大きい値になった場合、workflowをトリガーする。
これでデプロイタイミングでDatadog Eventが生成されます。
あとは 1, Event Overlays機能を使うで紹介したやりかたでデプロイタイミングを表示すればOKです。
このやり方のデメリットとしては、「Monitorで監視する都合上、デプロイタイミングを監視したいだけなのにWarn/Alert扱いになる」のでちょっとだけ気持ち悪い点です。 またWorkflow Automationの実行には料金がかかります。 ワークフロー実行100件あたり$12.50 なので、デプロイを大量に行っている会社では注意が必要です。
Workflow Automationはなかなか夢が広がる機能だなと感じていて、 https://app.datadoghq.com/workflow/blueprints (要Datadogログイン) に使い方例があるので見てみると面白いと思います。
まとめ
Datadogのグラフにデプロイタイミングを表示する方法を紹介しました。
なんとかDatadogだけで完結してデプロイタイミングを表示できないか考えていたので、 time_between_deployments メトリクスとWorkflow Automationを組み合わせることでできて楽しかったです。
速く、もっと速く!Docker Build Cloudでイメージビルド時間を短縮する

2024/1/23に Docker Build Cloudが発表されました
早速Docker Build Cloudを試してみました
Docker Build Cloudとは
サイト: https://www.docker.com/ja-jp/products/build-cloud/
ドキュメント: https://docs.docker.com/build/cloud/
イメージビルドをDocker社のCloud環境で行える機能です。 これによりどのようなメリットがあるかというと
- イメージビルドキャッシュの共有
- ローカルでイメージビルドするとき、もし他のユーザがビルド済みであればそのキャッシュを使うことができビルド時間が短縮できる
- CI環境では毎回サーバーが違うため
--mount=type=cacheが効かないがDocker Build Cloudであれば効く(!!) - ビルドキャッシュが存在するため
--cache-fromのようにregistry cacheを使わなくてもよい。通常registry cacheを使うとかなりビルドが速くなるがregistry cache自体をpullする時間, pullしたイメージをextractする時間に地味に時間がかかるがそれがなくなる。
- マルチアーキテクチャビルドが可能
- CIツールとのシームレスな統合
- ローカルのDockerやDocker Compose、GitHub ActionsやCircle CIなどのCIサービスと簡単に統合ができる
デメリットは、
- Docker Build Cloudでビルドしたイメージをpullする時間がかかる
- ただ変更があったimage layerだけがpullされるのでpullされるimage layerサイズが小さい場合はすぐ終わる
- 2024/02/03現在 US Eastリージョンしかないため、Asiaからpullすると非常に時間がかかる。今後EuropeやAsiaリージョンのサポート予定
- ビルドコンテキストをDocker Build Cloudに転送する時間がかかるケースがある
.dockerignoreを適切に設定していればビルドコンテキストサイズはそれほど大きくならないはずですが、何かしらの理由で大きなサイズの場合転送時間がネックになる可能性はあります。
- planに含まれているビルド時間を超えてビルドしたい場合はビルド時間購入料金がかかる
料金に関して
無料PlanのDocker Personalだと 無料ビルド時間は 50分/月 です。かなり少ないですね。
Docker Teamに入っていれば 400分/月 のビルド時間が付与されますが、これは組織アカウント単位であり、ユーザ数あたりではないので注意。
このように無料付与枠がかなり少ないので本格的にDocker Build Cloudを使用する場合は Docker Build Cloud Team Planに入る必要があります。
年間払いだと $5/ユーザー/月、 月払いだと $6/ユーザー/月。
付与されるビルド時間は 200分/ユーザー/月 です。
これでも足りない場合はビルド時間を追加購入ことができます。
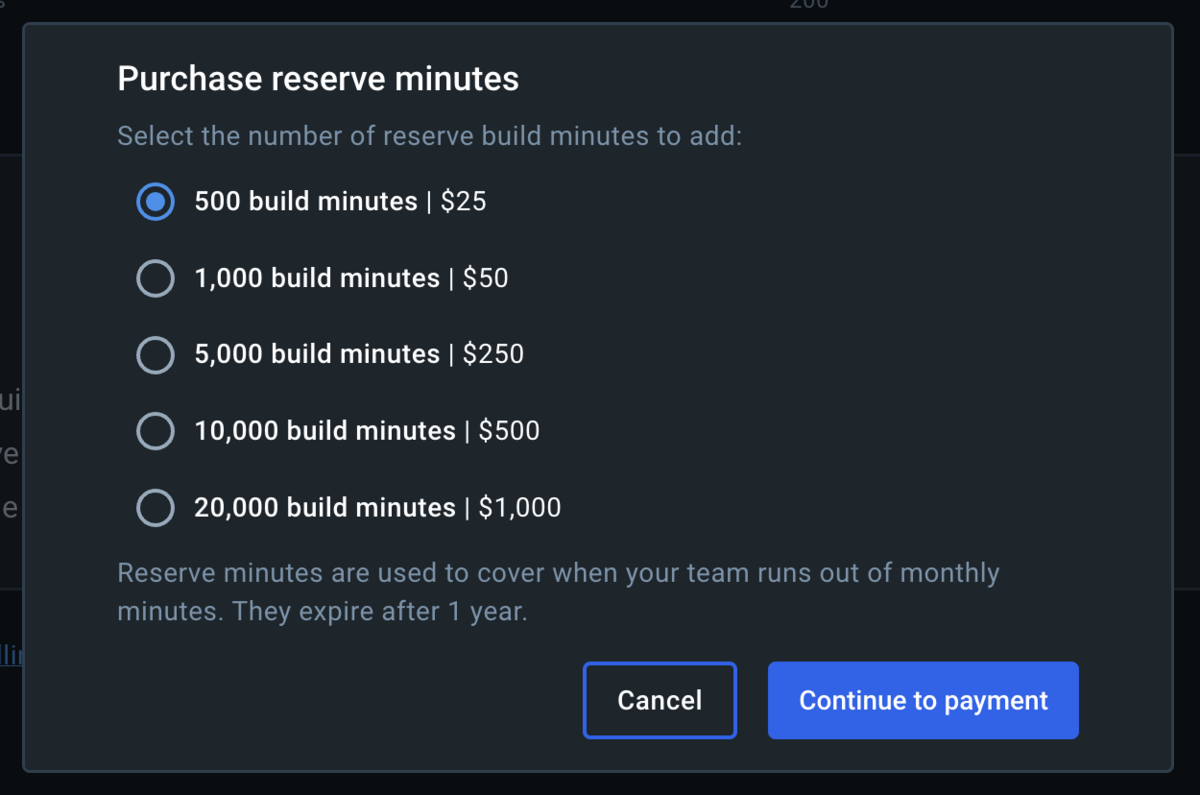
10,000分購入しても$500なのでかなり安い印象。
ちなみに、Docker Personal Planの無料枠の50minを使い切るとビルド時に
ERROR: failed to solve: FailedPrecondition: build cannot proceed build minutes limit of 50 reached
というエラーがでました。
使い方
https://build.docker.com/ にアクセスし、自分のprofileを選択します。

するとこういう画面がでるのでCreate new cloud builderからcloud builderを作成します。(この画面ではすでにmy-builderというcloud builderを作成済み)
作成したcloud builderをクリックすると、以下のような画面になります。
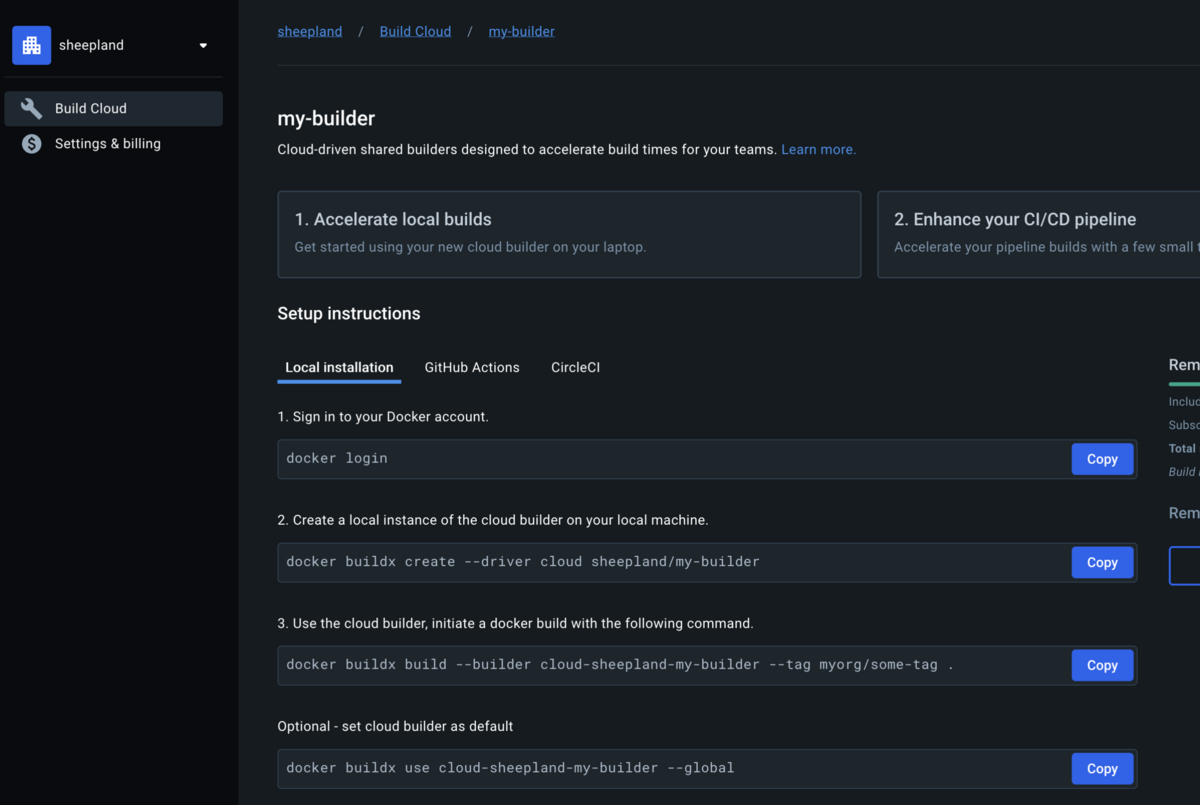
あとはSetup instructionsに表示される内容に沿って進めば簡単にDocker Build Cloudが使用できます。
実際速くなるのか?
イメージサイズが680MBになるDockerfileを使って試してみました。
ローカルでの使用
ローカルでのイメージビルドにDocker Build Cloudを使うメリットの一つはビルドキャッシュを共有出来る点です。
チームで開発をしている場合、フルビルドする場合イメージビルドに時間がかかります。
ビルドキャッシュを共有できれば他の人がすでにビルドした結果をpullすればよくなります。かなりイメージビルドが速くなりそうですよね。
しかし試してみると、Docker Build Cloudでビルドされたイメージをローカルにpullするのに長い時間がかかりました。
680MBのイメージをまるまるpullするのに6分くらい。更新されたimage layerだけをpullする場合でも330MBのサイズで190sくらい。更新されたimage layerのサイズが小さければ(1MB以下)なら数秒で終わりました。
これはDocker Build Cloudが2024/02/03現在、US Eastリージョンしかないため転送速度に時間がかかっているものと思われます。今後EuropeやAsiaリージョンのサポート予定だそうです。
Asiaリージョンのサポートがされてローカルでのpullが速くなればローカルでのDocker Build Cloudの使用も現実的になってくるかと思います。
CI上での使用
今回はCircleCIで試しました。
CircleCIはサーバーがUSリージョンにあるため、Docker Build Cloudでビルドしたイメージのpullにそれほど時間がかからないと見込んだからです。(GitHub Actionsは未調査)
CI上でのイメージビルドにDocker Build Cloudを使うメリットの一つはローカルでの使用と同様にビルドキャッシュを共有出来る点ですが、ポイントがローカルとは若干異なります。
- Docker Build Cloudサーバーにビルドキャッシュ存在するため
--cache-from,--cache-toのregistry cacheを使用しなくてよい。これによりregistry cacheイメージをpull&pushする時間, pullしたimageをextractする時間を削減できる --mount=type=cacheが効く- たとえregistry cacheを使っていたとしてもアプリケーションで使うパッケージを更新した場合、ビルド時間がかかっていました。
--mount=type=cacheを使うと追加/変更されたパッケージのみインストールすればよくなるためビルドが速くなりますが、CIでは毎回サーバーが異なるため--mount=type=cacheが使えないという課題がありました。Docker Build Cloudではビルドキャッシュが使えるため--mount=type=cacheが効きます。これによりアプリケーションで使うパッケージ更新時のイメージビルドが速くなります。
- たとえregistry cacheを使っていたとしてもアプリケーションで使うパッケージを更新した場合、ビルド時間がかかっていました。
またもう一つのメリットはCIのサーバースペックを下げられる点です。イメージビルドを高速に行うにはサーバースペックが要求されるため、例えばCircleCIではresource classで大きめのclassを指定していた人も多いかと思います。Docker Build Cloudを使うとDocker Build CloudのサーバーはDocker Build Cloud Team Planの場合16 vCPU、32GB RAMのサーバーが割り当てられます。これによりCI側のサーバースペックを下げることができコスト削減ができる可能性があります。
さてローカルではDocker Build Cloudでビルドしたイメージのpullに時間がかかっていましたが、CircleCI上では680MBのイメージをまるまるpullするのに約20s、更新されたimage layerだけをpullする場合でも330MBのサイズで約10sでした。非常に速いですね。18倍も速いです。ただこれはDocker Build CloudのサーバーがAWS上にあり転送処理がAWSネットワーク内ですんでいるためかもしれません。
また--mount=type=cacheの指定も効いており、パッケージの更新処理も非常に速いです。registry cacheも必要ないためシンプルになります。
キャッシュサイズ
注意する点があるとすればビルドキャッシュサイズになります。
Docker Build Cloudではビルドキャッシュが保存されるわけですが、Docker Build Cloud Team Planの場合最大で200GiBになります。もし数多くのイメージをビルドする場合キャッシュ上限に達してしまう可能性があります。
なおキャッシュ上限に達すると、古いキャッシュは自動的に削除されます。
See: How do I manage the build cache with Docker Build Cloud?
FAQ
https://docs.docker.com/build/cloud/faq
まとめ
自分もそうですが、CI上でのイメージビルド高速化に苦労している人は少なくないと思います。ビルドキャッシュさえ存在すれば細かいことを考えずにすむのになと…よく思っていました。
Docker Build Cloudを使えば手軽かつ安価にイメージビルドの高速化ができそうです。
Productionで使われているイメージビルド処理が速くなるかは実際に試してみないと分からない部分もあるので仕事で検証をしていきたいと思います。
OpenSearchの手動スナップショットリポジトリ登録スクリプトをRubyで書く
OpenSearchで手動スナップショットを作成するためには、事前にスナップショットリポジトリの登録をしなければなりません。
公式ドキュメントのサンプルにはpythonのコードが掲載されています。
Using the sample Python client
region = 'ap-northeast-1' service = 'es' # AWSの認証情報を取得 credentials = Aws::CredentialProviderChain.new.resolve aws_signer = Aws::Sigv4::Signer.new(service: service, region: region, credentials_provider: credentials) host = 'OpenSearchドメインエンドポイント' path = '_snapshot/スナップショットリポジトリ名' url = URI(host + path) bucket_name = 'スナップショットS3バケット名' role_arn = 'スナップショット IAM Role ARN' payload = { type: 's3', settings: { bucket: bucket_name, region: region, role_arn: role_arn } }.to_json # AWSの署名付きリクエストを作成 signed_request = aws_signer.sign_request( http_method: 'PUT', url: url.to_s, headers: { 'Content-Type' => 'application/json' }, body: payload ) headers = signed_request.headers headers['Content-Type'] = 'application/json' response = Faraday.put(url, payload, signed_request.headers) puts response.status puts response.body
AWSの認証情報を取得の部分は各環境に応じて変更してください。
参考: AWSのSigV4署名を付与してIAM認証のAPI GatewayにHTTPリクエストを送るRubyとGoのサンプルコード #Ruby - Qiita
OpenSearchでVPC内にあるドメイン同士でRemote Reindexをする
はじめに
Amazon OpenSearch Serviceで、同一VPC内にあるドメイン同士でRemote Reindexをする方法を紹介します。
まず、公式ドキュメント docs.amazonaws.cn
前提条件
注意すべきは前提条件の部分です。
・ドメインでデータ ノードに T2 または T3 インスタンス タイプを使用している場合、リモート再インデックスは使用できません。
検証用でT3インスタンスを使っている場合はインスタンスタイプを変更しましょう。
リモートドメインは、ローカルドメインからアクセス可能である必要があります。VPC 内に存在するリモートドメインでは、ローカルドメインに VPC へのアクセスが必要です。このプロセスはネットワーク構成によって異なりますが、VPN またはマネージドネットワークへの接続、もしくは、ネイティブの VPC エンドポイント接続の使用が必要となる場合がほとんどです。詳細については、「VPC 内で Amazon OpenSearch Service ドメインを起動する」を参照してください
これは分かりにくいですが非常に重要です。次で説明をします。
組み込みのVPCエンドポイント接続機能
Migrating Amazon OpenSearch Service indexes using remote reindex - Amazon OpenSearch Service に説明がありますが、同一VPC内にあるドメイン同士であっても、組み込みのVPCエンドポイント接続機能を使ってローカルドメイン(データのコピー先)からリモートドメイン(データのコピー元)へのアクセスができるようにする必要があります。(てっきり同一VPC内にあれば設定いらんやろと思って読み飛ばしていたら必要でハマりました…)
組み込みのVPCエンドポイント接続機能とは?と思いますが、 このセクションの Reindex data with the Amazon Web Services Management Consoleにやり方が書いてますので、Remote Reindex APIの実行手前までそれ通り進めます。コンソールをぽちぽちやれば終わるはずです。
Remote Reindex API
さて、VPCエンドポイント接続設定が終わったらいよいよRemote Reindex APIの実行です。
ドキュメントには以下のように書かれていると思います。
POST _reindex
{
"source":{
"remote":{
"host":"endpoint",
"username":"username",
"password":"password"
},
"index":"remote-domain-index-name"
},
"dest":{
"index":"local-domain-index-name"
}
}
きめ細かなアクセスコントロールを有効にしていて、かつユーザー管理にIAMを使用していない場合でなければusername, paswordはパラメーターとして渡さなくて大丈夫なはずです。
そうすると以下のようになりますが、
POST _reindex
{
"source":{
"remote":{
"host":"endpoint"
},
"index":"remote-domain-index-name"
},
"dest":{
"index":"local-domain-index-name"
}
}
実行すると
"error" : {
"type" : "null_pointer_exception",
"reason" : null
}
といったエラーが返ってきます。
ドキュメントには書いてないですが、"external": trueオプション必要です。
medium.com
の記事を見てやっとエラーが解消できました…。
最終的に以下の形になります。
POST _reindex
{
"source":{
"remote":{
"host":"endpoint",
"external": true
},
"index":"remote-domain-index-name"
},
"dest":{
"index":"local-domain-index-name"
}
}
なお"host":"endpoint"の部分の endpointは OpenSearchのドメインエンドポイントにport番号:443をつける必要があります。
つまりこんな感じになります。
"host": "https://hogehoge.ap-northeast-1.es.amazonaws.com:443"
まとめ
Amazon OpenSearch Serviceで、同一VPC内にあるドメイン同士でRemote Reindexをする方法を紹介しました。 remote reindexは snapshot&restoreと比べると snapshot用のS3バケットの作成, snapshotリポジトリの登録、それ用のIAM Role作成などをしなくていいので楽ですね。
ECRにリモートキャッシュ(--cache-to)のmode=maxでイメージプッシュする
2023/11/16 に BuildKit クライアント用の Amazon ECR でのリモートキャッシュサポートの発表 | Amazon Web Services ブログ
という記事が発表されて、イメージビルド時のcache-toのオプションmode=maxが使えるようになった。
待望のアップデート。このissueを見たらどれだけ待ち望まれていたかが分かる。
以前まではECRはリモートキャッシュマニフェストに対応していなかったため、リモートキャッシュ先にECRを指定する場合はtype=inlineを指定する必要があった。(参考: Github Actionsのdocker/build-push-actionのcache-toにECRを指定する)
type=inlineだとmode=minしか指定出来ない。mode=minだと結果イメージのレイヤーしかキャッシュされず、マルチステージビルドを使用している場合中間イメージがキャッシュされず、イメージビルドが速くならないという問題があった。
max=modeはすべてのレイヤーをキャッシュするので、中間イメージが更新されてもキャッシュが効いてイメージビルドが速くなる。
リモートキャッシュに関しては Cache storage backends | Docker Docs を参照。
設定例
GitHub Actions
- name: Login to Amazon ECR id: login-ecr uses: aws-actions/amazon-ecr-login@v1 - uses: docker/build-push-action@v3 with: push: true tags: ${{ steps.login-ecr.outputs.registry }}/${{ env.REPOSITORY_NAME }}:${{ github.sha }} provenance: false cache-from: type=registry,ref=${{ steps.login-ecr.outputs.registry }}/${{ env.REPOSITORY_NAME }}:buildcache cache-to: type=registry,mode=max,image-manifest=true,oci-mediatypes=true,ref=${{ steps.login-ecr.outputs.registry }}/${{ env.REPOSITORY_NAME }}:buildcache
CircleCI
- run: name: create builder instance # ビルダーインスタンスを作成しないとエラーになる command: docker buildx create --use - aws-ecr/build_and_push_image: account_id: ${AWS_ACCOUNT_ID} auth: - aws-cli/setup: role_arn: ${AWS_ROLE_ARN} region: ${AWS_DEFAULT_REGION} push_image: true region: ${AWS_DEFAULT_REGION} repo: ${REPOSITORY_NAME} tag: ${CIRCLE_SHA1} extra_build_args: >- --cache-from type=registry,ref=${REGISTRY_URL}/${REPOSITORY_NAME}:buildcache --cache-to type=registry,mode=max,image-manifest=true,oci-mediatypes=true,ref=${REGISTRY_URL}/${REPOSITORY_NAME}:buildcache --provenance=false
provenance=false にしている理由は docker/build-push-action v3.3.0で導入されたprovenanceオプションにまつわる問題 - chroju.dev を参照