例えば以下のような定例用のGoogleドキュメントがあったとします。

テンプレートが下のほうにあり、上にその週のアジェンダをどんどん追加していくスタイルのドキュメントです。 ローテーションで司会が変わっていきます。
この毎週のアジェンダ作成が面倒です。テンプレートからコピってきてその週の定例の日付を入力しその週の司会の人の名前を入れる必要があります。 面倒なので自動化しました。
メニューバーの「拡張機能」から「Apps Script」を選択します。

Apps Scriptのエディタが開いたらおもむろに以下のコードを貼り付けて保存します。
var templatePhrase = 'template'; var templateDateFormat = 'YYYY/MM/DD'; var mtgIntervalDays = 7; function onOpen() { const ui = DocumentApp.getUi(); ui.createMenu('アジェンダ') .addItem('テンプレート追加', 'addTemplate') .addToUi(); } const body = DocumentApp.getActiveDocument().getBody(); var previousParagraph; var templateParagraph; const templateParagraphs = []; function setup(body) { var inTemplate = false; body.getParagraphs().forEach((paragraph) => { if (!previousParagraph && paragraph.getText().startsWith('202')) { console.log("paragraph.getText()="+ paragraph.getText()); previousParagraph = paragraph; } if (paragraph.getText().startsWith(templateDateFormat)) { templateParagraph = paragraph; } if (paragraph.getText() === templatePhrase) { inTemplate = true; return; } if (inTemplate) { templateParagraphs.push(paragraph.copy()); } }) } function getFacilitator() { var facilitatorText = templateParagraph.getText().split(" - ")[1]; // console.log(facilitatorText); facilitators = facilitatorText.match(/(.*)/g)[0].slice(1, -1).split('→'); var facilitator; if (previousParagraph == null) { facilitator = facilitators[0]; } else { var previousFacilitator = previousParagraph.getText().split(" - ")[1]; facilitators.push(facilitators[0]); facilitator = facilitators[facilitators.indexOf(previousFacilitator) + 1] } // console.log(facilitator); return facilitator; } function getMtgDate() { var previousDate; if (previousParagraph == null) { previousDate = new Date(); } else { const previousDateStr = previousParagraph.getText().split(" - ")[0]; previousDate = Utilities.parseDate(previousDateStr, "JST", "yyyy/MM/dd"); previousDate.setDate(previousDate.getDate() + mtgIntervalDays); } var mtgDate = Utilities.formatDate(previousDate, 'JST', 'yyyy/MM/dd'); // console.log(mtgDate); return mtgDate; } function addTemplate() { setup(body); // テンプレートパラグラフの挿入 var horizontalRule = body.findElement(DocumentApp.ElementType.HORIZONTAL_RULE).getElement(); var horizontalRuleIdnex = body.getChildIndex(horizontalRule.getParent()) + 1; templateParagraphs.forEach((paragraph, i) => { if (paragraph.getType() === DocumentApp.ElementType.LIST_ITEM) { body.insertListItem(i + horizontalRuleIdnex, paragraph); } else if (paragraph.getText().startsWith(templateDateFormat)) { paragraph.setText(getMtgDate() + " - " + getFacilitator()); body.insertParagraph(i + horizontalRuleIdnex, paragraph); } else { body.insertParagraph(i + horizontalRuleIdnex, paragraph); } }); }
実装の内容を簡単に説明すると、templatePhraseと一致する部分を探しそれから下をテンプレートとしてコピー、ドキュメント内の区切り線(水平線)の下にテンプレートを挿入。このときその週の日付と司会を入れる。ようにしてます。
ドキュメントに戻ると、以下のようにメニューバーに「アジェンダ」→「テンプレート追加」というメニューが追加されているのが分かると思います。

一番最初に「テンプレート追加」を押すと許可を求められますが、許可してあげてください。 そして再度「テンプレート追加」を押すと今週のアジェンダが追加されます。
さて、毎回「テンプレート追加」を手動で押すのは面倒なので、自動化します。
Apps Scriptの左のメニューから「トリガー」を選択します。

そして「トリガーを追加」を選択し、実行する関数に「addTemplate」を選択します。
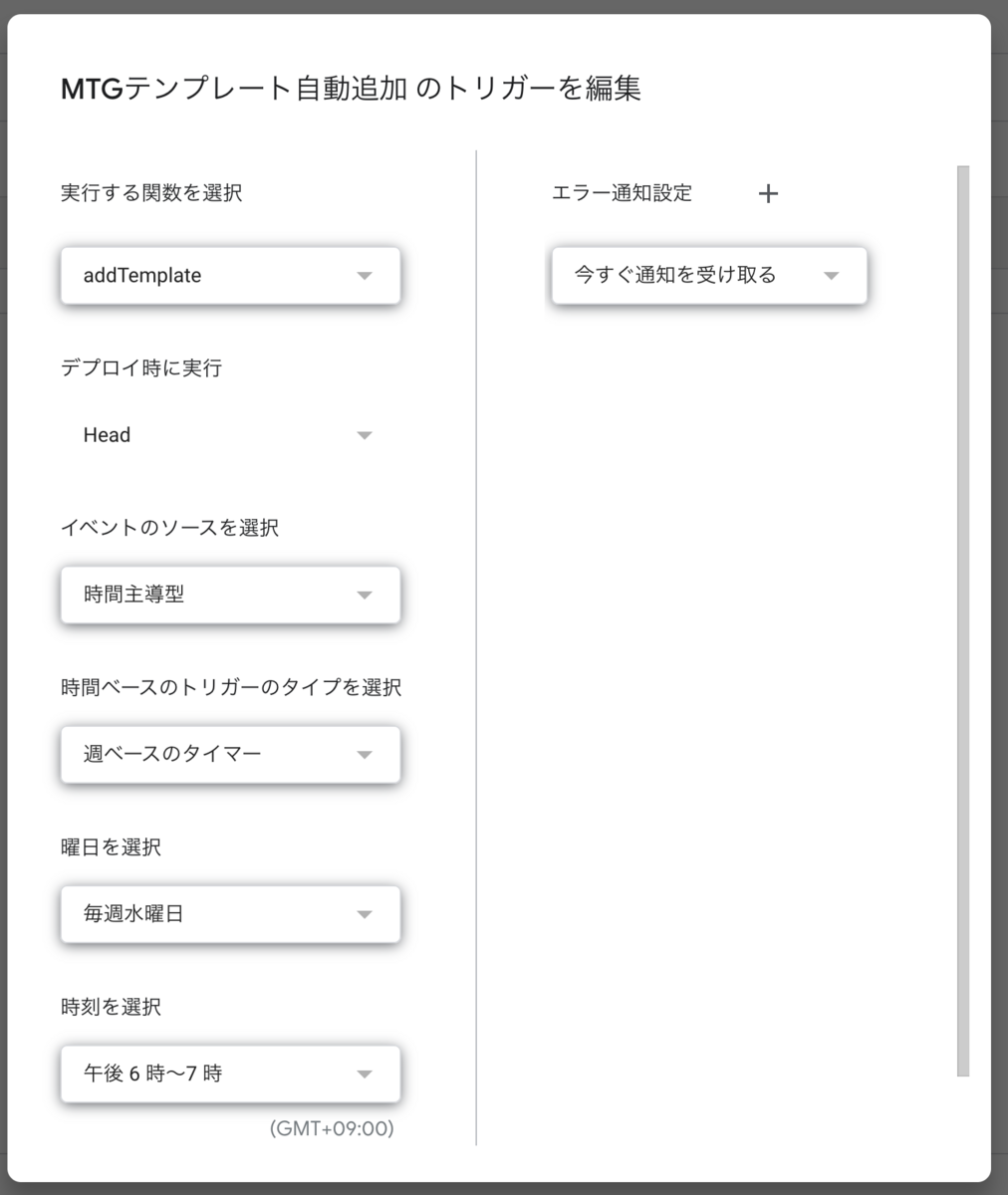
あとは実行したいスケジュール条件を入力します。定例MTGが終わった後実行するのがよいでしょう。
これで面倒な作業から解放されます。最高です。